The information model to end all information models
I am now beginning work on the second alpha iteration of the open-source ICA-AtoM software application.
I am working on a considerable upgrade to the underlying object and database model which supports the application. As the application matures and evolves it will be relatively easy to make changes and updates to the application modules and user interfaces. However, it will be difficult to make significant changes to the database model once the application goes into active deployment and people start entering information. Therefore, I better get this right now...
ICA-AtoM must be flexible enough to support a wide variety of potential uses. Firstly, as an archival description package for individual archival institutions as well as a union catalog application that can combine descriptions from multiple repositories (e.g. for UNESCO's human rights archives portal project).
Beyond that, I have high hopes that ICA-AtoM can evolve to become an even more universal information cataloging tool that can be used, for example, to manage personal digital archives (e.g. family photos, home movies, music collections, etc) as well as other reference resources that typically support archival collections (e.g. encyclopedias, dictionaries, bibliographies, reference libraries, web links, etc.).
Therefore, I want to be sure that the ICA-AtoM information model supports the International Council on Archives standards out-of-the-box. At the same time, I want it to be flexible enough to support additional information cataloging and classification needs. I want it to be open, extensible and to anticipate the future wave of semantic information organization and sharing.
Magic mystery tour of information architecture
That's why I've spend some mind-bending hours revisiting a number of information architecture standards, communities and research projects.
I've gone everywhere from Dublin Core to Microformats to Semantic Web to modified pre-order tree traversal to object relational mapping to METS to EAD to OAIS to the Monash Project to the UBC Project to Topic Maps and back to ISAD(G) and ISAAR(CPF).
The most amusing stop on this magic mystery tour of information architecture was dropping in on the Semantic Web vs. Microformats stand-off and flame war.
The most useful stop was the Topic Map community and a surprisingly relevant article written by a Microsoft architect.
Towards a supa-dupa information model
Somewhere in the back of my brain a universal information object architecture is slowly solidifying. I have, in fact, been thinking about and working on such a model for quite a number of years, starting 10 years ago with my first job out of archives school at a local software vendor and extending into my current consulting and doctoral research.I posted a high-level architecture diagram for an archives access system on this blog last year. Now I am getting into the nitty-gritty of the information model that would support such a system.
Some of the guiding principles or goals for this base information model are:
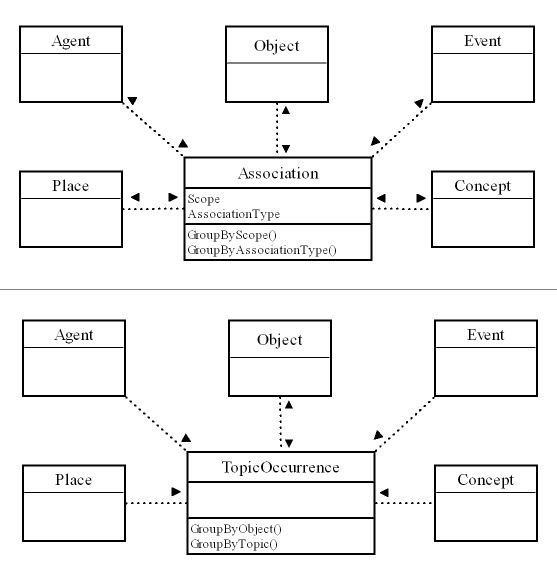
- There are five core entities: Objects, Agents, Events, Places and Concepts,
- By default, Object types include archival materials.
- By default, Agent types include archival record creators
- By default, Place types include archival repositories
- The user can define new category types for the five core entities (e.g. adding bibliographic materials or artifacts as a Object types)
- Associations and Topic Occurrences are two, parallel contexts in which core entities relate to each other.
- Associations are any type of relationships between core entities (e.g. 'is a child of', 'is a type of', 'is the creator of', 'occurred at', 'is storage location for')
- The user can define any type of association
- Topic Occurrences are instances when a core entity is used as an access point to describe and identify an Object as an information resource (e.g. Object XYZ is an information resource about Concept XYZ or about Place XYZ or about Agent XYZ).
- Associations are any type of relationships between core entities (e.g. 'is a child of', 'is a type of', 'is the creator of', 'occurred at', 'is storage location for')
- Objects can be used as Topic Occurrences for other Objects (e.g. A. Pallister's book Magna Carta the Legacy of Liberty is an information resource Object that is about the Magna Carta, another information resource Object.
- Core Entities, Associations and Topic Occurrences can be grouped and restricted to specific scopes or contexts (e.g. so that boundaries can be established between specific collections and taxonomies)
- Objects can exist in more than one form (i.e. analogue, digital or multiple copies of both) and in more than one place (e.g. real-world and online)
- online digital objects must have addressable URIs
- Core entities are represented by metadata profiles
- All information resource Objects can be described using at least Dublin Core metadata elements
- All Core Entities can be described at the logical/descriptive level using more than one metadata profile
- The administrative metadata for the storage and physical management of analogue and digital objects must be generic at the physical level
- The data model must be flexible enough to surface data stored in ICA-AtoM as EAD, EAC, Microformats, RDF or topic maps (e.g. as XSLT transformations or through REST APIs)
Now my challenge will be to implement these design principle and objectives in a functional and optimal web-based application. This means that the complexity has to be hidden from the user and the application can't slow down to a crawl to process a number of complex relationships or database queries.
This is what I'll be working on over the next few weeks using the Symfony framework, its Propel object-relationship mapping layer and the MySQL database engine.
I am sure I'll have to make some compromises and tweaks along the way (keep in mind that this list is simply some research notes generated during my best practice analysis) but hopefully this investment will pay off in the long run to make the ICA-AtoM information model as flexible and powerful as possible.